三、关于 GPT 模型的哲学思考
3.1 程序语言与自然语言
实际上人类创造的语言可以分为两类,一类是 自然语言,它是人与人之间沟通的语言,一类是 程序语言,是人与机器之间沟通的语言。
这两类语言有着非常大的不同。程序语言的范式非常强,需要遵循严格的语法规则,自由度小。自然语言的范式非常弱,不用遵循严格的语法规则,自由度大。
两类语言的差异,使得程序语言更加易于被处理。实际上 gcc 编译器,jvm 虚拟机,python 解释器等程序都是能处理程序语言的程序。
相比之下,自然语言的处理更加复杂和困难。近几十年来,人们一直在想办法使用程序来理解自然语言。ChatGPT 等大型语言模型的出现让人们看到了解决自然语言理解任务的曙光。
在一定程度上,ChatGPT 打破了自然语言处理和编程语言处理之间的壁垒,这得益于它强大的编程能力。它能够理解人类用自然语言表达的需求,并生成对应的程序语言代码。这一特性完全打破了程序语言和自然语言的次元壁,使得两种截然不同的语言之间的交流成为了可能。程序员作为自然语言和程序语言的中间「翻译者」,必然会因为 ChatGPT 的出现受到极大的「影响」。
![图片[1]-ChatGPT 实用指南(三)-SPHAI人工智能聊天 | GPT-3.5](https://ai.sph.net/wp-content/uploads/2023/04/fafe14a4de44638.webp)
除此以外,作为一个概率型的语言模型,它甚至能模仿 Bash、Python、Java、GCC 等元程序去运行程序语言的代码,甚至能直接根据自然语言的描述,完成对应的任务给出几乎确定的结果。这些特性让我们看到了大型语言模型的潜力,它可能直接改变编成的范式,直接面向自然语言编程,而不是面向程序语言编程。
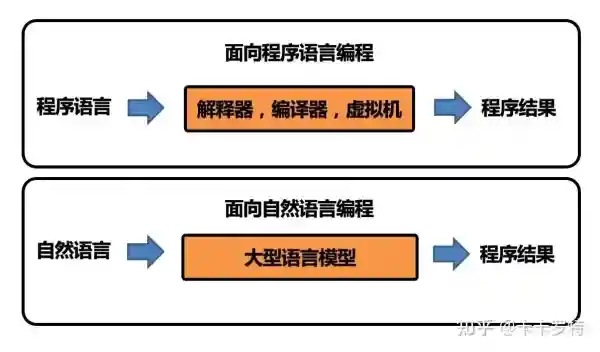
下面以一个简单的例子说明两者的区别:
面向程序语言编程:

面向自然语言编程:

3.2 涌现性与还原论,演绎与归纳
这小节我们讨论 4 个经典的哲学概念。首先我们来看涌现性与还原论。
涌现性 和 还原论 是两个哲学上的概念。
还原论是指将复杂的系统分解为更简单的组成部分来进行理解和研究的一种方法。这种方法认为整个系统的特征可以通过分析其组成部分的特征来解释。还原论在自然科学和工程领域中被广泛应用,例如分子生物学中的基因还原论,物理学中的微观还原论等。
涌现性则是指当简单的组成部分结合在一起时,整个系统呈现出的新的特征和现象。这种特征和现象不能简单地通过分析组成部分的特征来解释,而是需要考虑整个系统的复杂性和相互作用。涌现性在生命科学、社会科学和哲学中都有广泛的应用。
以往,人们一直希望通过还原论的方式来构造人工智能(AGI)。因此,在过去十几年的深度学习发展浪潮中,人们一直在将智能拆分成不同的子领域,然后分别解决这些子领域。例如在计算机视觉中,人们提出了图像分类、目标检测、语义分割、图像理解等子领域;在自然语言处理中,人们提出了文本分类、实体识别、文本生成等子领域。
然而,ChatGPT 的出现让人们突然意识到,大型模型能够涌现出一些人类意想不到的能力,例如大型语言模型中的上下文学习能力。这使得大型语言模型能够大一统所有的自然语言处理任务。虽然涌现性的原因还无法解释,但当网络结构足够复杂、数据量足够多、算力足够大时,神经网络也许真的能够涌现出智能。
最后,让我们再讨论一下演绎和归纳的关系。
在本书开篇,我们已经介绍了演绎和归纳。GPT 模型显然是一种纯归纳的方式进行的训练,即在大量的文本数据集上,「归纳」出用前文的 token 预测下一个 token 的「规律」。
然而,令人惊讶的是,由纯归纳原理训练出的 GPT 模型展现出了强大的推理能力,即演绎能力。换句话说,用纯归纳的方式构建了一个具有一定演绎功能的系统,这在过去是难以想象的。
3.3 模型的参数与生物的基因
在我的书籍《Enlighten AI·数学基础》和《Enlighten AI·机器学习》中,曾经提到了如下的类比观点:
生物进化 是从无穷的基因组合中寻找最优的基因以适应环境。
人工智能 是从无穷的参数空间中寻找最优的参数以适应任务。
目前,许多学者也在思考是否可以将大型语言模型的学习过程与人类的学习过程做比较。大型语言模型的学习过程包含两个部分:
- 通过 自监督学习 来更新模型的参数。
- 通过 上下文学习 快速掌握新的技能。
第一种学习涉及模型参数的更新,需要大量的数据、算力和时间。而第二种学习则不会更新模型的参数,仅通过适当设计的提示(Prompt)就能让模型展现出魔法般的效果。
也许我们可以将模型的参数类比于人类的基因。构建大型模型的过程就像在模拟人类的进化,构建基因的过程,最终构造出的大型模型就好比一个具有学习能力的婴儿。婴儿出生后的学习能力就类似于大型模型的上下文学习。
然而,这种类比仍然是不恰当的。因为神经科学家通过实验发现,人类的神经回路并不是自出身起就不变的,实际上,人的后续学习会影响大脑神经回路的结构。
因此,大型模型的参数训练加上下文学习(即 Prompt)的范式也许有一定的合理性,但离智能的最终形态(例如像人一样,后天的学习也会影响先天的神经回路)也许还有一定的距离。
3.4 GPT 的局限性
这部分参考微软发表的论文《Sparks of Artificial General Intelligence: Early experiments with GPT-4 》
GPT 模型使用前文 token 预测下一个 token,这种预测方法使得 GPT 模型是一种线性思维,无法像人一样在思考期间进行回溯思考。
例如,当人回答以下问题时:
问:150 和 250 之间有多少个质数?人可能会在脑中不断地回溯和更新自己心算的答案。如果不给 ChatGPT 适当的引导(例如前面提到的思维链提示),ChatGPT 常常会犯错。
另一方面,线性思维使得 ChatGPT 没有提前规划的能力。例如,如果让 ChatGPT 生成一首英文诗,要求诗的第一句话和最后一句有相同的词,但顺序相反。GPT 在生成第一句话时并不会考虑到最后一句话的要求,这使得最后一句话的生成常常存在语法错误。原因在于 ChatGPT 的思考是线性的,没有进行提前的规划。在这方面,人类远远胜过 GPT 模型。
除了自身结构的局限性外,像短期记忆和长期记忆也是 ChatGPT 的短板。虽然我们在前面用了一些技巧规避了部分短板,但它和人类相比还是略逊一筹。人类可以将短期记忆通过训练和强化转化为长期记忆,而 ChatGPT 要达到完美的长期记忆只能通过参数的 finetune。
最后,作为由神经网络构成的模型,ChatGPT 不可避免地存在着 幻觉问题 和 偏见问题。
幻觉问题指的是它有时会产生虚假的答案,这些答案很难与真实答案区分开来。例如,它可能会生成一篇从未存在过的论文或新闻文章。
偏见问题指的是它会对一些问题产生偏见。例如,它可能会倾向于认为护士是女性而不是男性,这种偏见超出了真实世界中护士男女比例的范围。
目前,我们无法完全避免这些问题。这些问题也是让大型语言模型参与到人类真实社会中的决策时存在的风险。
3.5 GPT 模型的未来
在第3.3节中,我们介绍了GPT模型的局限性。我认为这些局限性正是GPT未来需要解决的问题。
在 ChatGPT 的使用层面,需要解决短期和长期记忆的问题,尤其是长期记忆的问题。前面提到的方法只能部分解决长期记忆的问题,因此如何通过低成本的 finetune 方法甚至不通过 finetune 就将长期记忆持久化进模型中是一个非常重要的研究方向。
在 ChatGPT 的风险控制层面,需要解决大型语言模型的幻觉和偏见问题。与编译器和解释器不同,大型语言模型的语法错误不会导致模型报错。因此,如何识别大型语言模型产生的幻觉是非常重要且棘手的问题。此外,文本数据中存在大量偏见,如何尽量减少大型语言模型的偏见也是重要的研究方向之一。
在 ChatGPT 的训练范式层面,需要解决自回归模型的局限性。尽管该范式结合transformer 神经网络结构已经涌现出了强大的上下文学习能力,但仍然存在工作记忆偏小以及无法回溯和提前规划的缺陷。这可能需要一种新的训练范式,甚至新的神经网络结构才能彻底解决。
最后,多模态数据的引入一定是 ChatGPT 未来的重要方向。人类从出生起就接受各种外部输入,包括文字、语音、图像(视频)等等。笔者相信,ChatGPT 无论是在训练还是推断、输入还是输出,都将向多模态数据的方向发展。目前,GPT-4 已经可以接受图像输入(截至2023年4月8日仍未向公众开放)。笔者相信随着算力的提高和数据量的增加,GPT 对多模态数据的支持只是时间问题。

请登录后查看评论内容