二、ChatGPT 使用技巧
2.1 提示工程
2.1.1 什么是提示工程
从本小节开始,我们将 ChatGPT 视为一个具有一定智慧的“人类”,并将尽可能地将 ChatGPT 的行为与人类的行为进行类比。这样才能更好地理解为什么我们需要新增一些“概念”并设计一些“工具”,以帮助它更好地工作。
在近年来的自然语言处理发展过程中,“提示”一词的含义发生了特别大的变化 [①]。在本书中,我们只从使用者的角度来学习和研究提示。
在前面的 1.3.2 节中,我们讲解了大型语言模型的一个神奇特性,即上下文学习。这个神奇的特性似乎赋予了大型语言模型快速“举一反三”的能力。要想进行反三,必须先有好的举一。就像如何向人类提出好的问题并给出好的示例一样,这直接关系到回答的质量。提示工程的目标是如何更好地向 ChatGPT 提问、更好地描述和表达问题。
下面是提示工程较为官方的定义:
提示工程 是创建一组指令和文本,作为大型语言模型的输入。通过这些指令和文本来引导大型语言模型完成我们的特定需求。好的提示工程和差的提示工程产生的结果有天壤之别。好的提示就像魔法咒语一样,能让大型语言模型产生神奇的效果。
遗憾的是,提示工程仍然是一门经验性的学科,我们暂时没有理论支持来指导我们如何设计出好的提示。因此,我们只能通过不断探索和积累经验性的结论和方法来学习和发展提示工程。
2.1.2 提示的构成
提示的形式千差万别,理论上我们可以设计出无数的提示。然而,本文将会介绍常见的提示方式,这些提示利用大型语言模型辅助我们完成特定的语言任务。
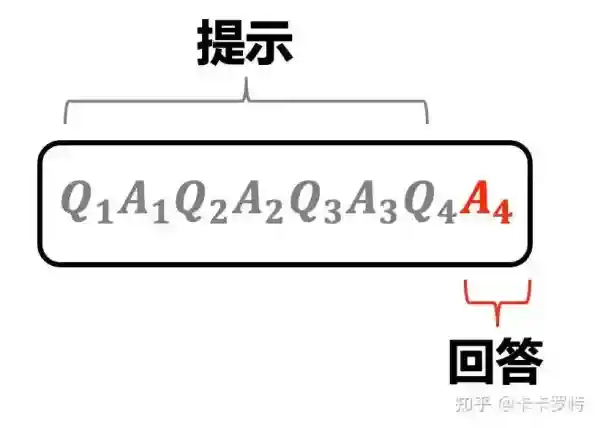
一般情况下,我们可以将提示分为 4 部分:
- 指令:表示你想让大型语言模型完成的任务。
- 输出要求:表示你对大型语言模型输出的要求。
- 上下文背景:一些需要给到大型语言模型的外部信息,例如单样本,少样本学习中的示例。
- 问题:需要大型语言模型回答的具体问题。
实际上,上面的提示和对应的回答仅仅是单轮对话的例子。ChatGPT 本身是一个多轮对话系统。因此,作为用户,在和 ChatGPT 进行多轮对话时,每次 ChatGPT 给出的最新回答都是基于你之前提出的问题以及你们的历史对话内容。换句话说,利用多轮对话,我们可以进一步引导 ChatGPT,甚至纠正 ChatGPT 已经犯的错误。
单轮对话的提示:
![图片[1]-ChatGPT 实用指南(二)-SPHAI人工智能聊天 | GPT-3.5](https://ai.sph.net/wp-content/uploads/2023/04/212bdf1f497a57e.webp)
多轮对话的提示:
关于如何设计更具体的 Prompt,你可以参考这本书《The Art of Asking ChatGPT for High-Quality Answers》。书中提供了许多 Prompt 模板,可以供你使用。
2.2 工作记忆
2.2.1 什么是工作记忆
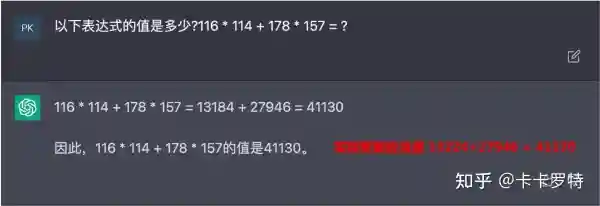
请读者不用笔和工具计算下面的算式:
(2.1)4×7+8×8 4\times7+8\times8 \tag{2.1}
回想一下你的计算过程。大部分人会先计算出 4×74\times7 ,然后将结果存放在想象中的一个空间中,接着再将 8×88\times8 的结果放入同一个空间中。最后在这个想象的空间中,将两个结果相加得到最终的答案。
这个想象的「空间」,也就是工作记忆(working memory),在上述任务中直接决定了你的心算能力。工作记忆在这个任务中发挥了两个作用。一方面,它将任务拆分成子任务,规划完成任务所需的步骤。任务规划是指完成一个任务需要完成多个子任务,因此需要一定的任务规划能力。任务规划的过程可能也是在工作记忆中完成的。例如,在这个问题中,应该先分别计算两个乘法的和,再将结果相加。除此之外,许多推理问题也需要任务规划能力,因为推理通常涉及多个步骤,需要规划好每一步推理要做的事情。另一方面,在工作记忆中人类可以修改计算的中间结果,以确保最终的输出结果的准确性。
遗憾的是,目前 ChatGPT 的神经网络结构和训练方式决定了它的工作记忆相对较小,这也可能解释为什么 ChatGPT 不太擅长做计算和任务规划。
虽然 ChatGPT 的工作记忆有时候受限,但并不意味着我们没有缓解这个限制的方法。
2.2.2 如何增加工作记忆
同样的,如果让你计算下面的算式:
(2.2)4×7+8×8 4\times7+8\times8 \tag{2.2}
如果让你用笔和纸,你可以轻易的得出正确答案。笔和纸将计算和推理的中间过程记录了下来,它极大的减少了我们对工作记忆的占用。
同样的,我们可以用提示(prompt)来引导 ChatGPT 将中间步骤都记录下来,以减少它对工作记忆的占用,进而减少它犯错的几率。
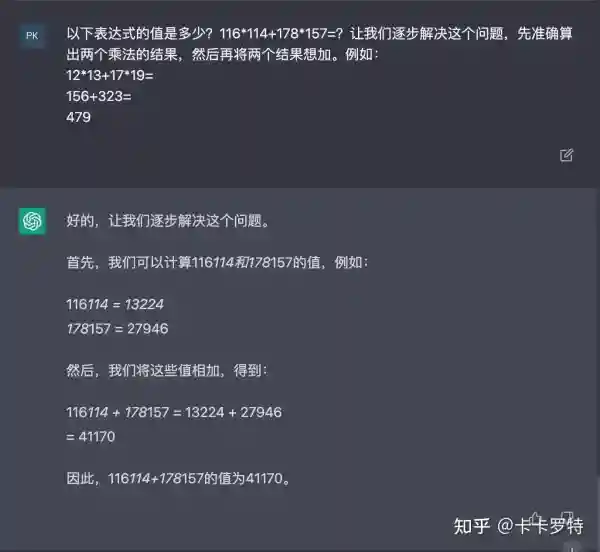
这种引导方式被称为 思维链提示 (Chain of Thought)。实际上,除了思维链提示外,研究者还提出了 ReAct 提示和 self ask 提示。它们的本质思想都是通过设计提示来减少ChatGPT对工作记忆的负担。稍有不同的是,ReAct 和 self ask 进一步引入了外部工具,这将在后面的章节中进行讲解。
2.3 短期记忆
2.3.1 什么是短期记忆
实际上,ChatGPT 模型是 无状态 的。每次我们调用 OpenAI 的接口并开始与ChatGPT 进行对话时,我们都开始了一次全新的对话,我们通常将这个对话称为 会话。那么,为什么用户会感觉到 ChatGPT 记得前面的互动内容呢?
其实这点我们在 1.3.1 小节做了解读。ChatGPT 每次的输入是用户之前多轮对话的历史,这些历史就是输入的提示(prompt),从而让用户感觉 ChatGPT 在和他进行连续的对话。
![图片[2]-ChatGPT 实用指南(二)-SPHAI人工智能聊天 | GPT-3.5](https://ai.sph.net/wp-content/uploads/2023/04/db952e173f1ac6a.webp)
多轮对话的历史,我们常称为 短期记忆,它可以视为提示(prompt)的一部分。短期记忆可以帮我们塑造不同性格和能力的 ChatGPT。虽然大家使用的 ChatGPT 的参数都是同样的,但不同的短期记忆能把 ChatGPT 「调教」成不同的性格,塑造成不同的工具。
让我们做一个不太恰当的类比,帮助读者进一步理解短期记忆。小吴是刚毕业的大学生,通过二十几年的教育和学习,他掌握了很多的知识,这些知识好比 ChatGPT 的参数,已经牢牢存储在了他的脑里,形成了各种能力。当踏上工作岗位后,他需要快速掌握一些工具,他工作中的师傅通过和他的对话和互动将这些知识传授给了他,这些知识还未牢牢存储在他的脑里,而是存储在短期记忆中。
2.3.2 短期记忆的问题
短期记忆确实可以帮助我们打造不同性格和能力的 ChatGPT,但是存在两个问题:
- 每次与 ChatGPT 的交互都会带上之前的对话内容(除非重新开启一次对话,此时 ChatGPT 的短期记忆相当于被清空)。随着对话轮数的增加,所需的 token 数量会越来越多。因为输入的提示(即历史对话)也会占用 token 的消耗量,因为它们将进入神经网络参与计算。
- 随着与 ChatGPT 的对话轮数增加,短期记忆的内容也会增加。然而,ChatGPT 使用的神经网络结构的输入是有限的。目前,GPT-3.5 最多只能包含 4096 个 token,而 GPT-4 最多能包含 32000 个 token。
这里稍微说明一下 OpenAI 的计费方法。OpenAI 主要根据 token 的消耗量计费,消耗的 token 越多,花的钱越多。消耗的 token 来自两个地方:
- 输入的提示,即
Prompt。 - ChatGPT 生成的文本,常被称为
Completetion。
2.3.3 如何解决短期记忆的问题
要解决短期记忆持续膨胀的问题,可以采取尽可能减少短期记忆 token 数量的方法。但是需要确保尽可能保留短期记忆的核心内容。通常有以下几种方法来解决短期记忆问题。
方案一:
选择一个窗口,只保留最近 k 轮对话内容。
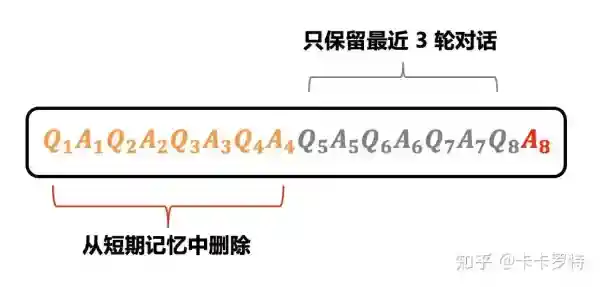
这个策略基于如下假设:过于久远的对话不太重要,而距离当前时间更近的对话则更加重要。
方案二:
利用大型语言模型强大的文本摘要能力,将对话历史和新增的互动内容进行摘要提取。
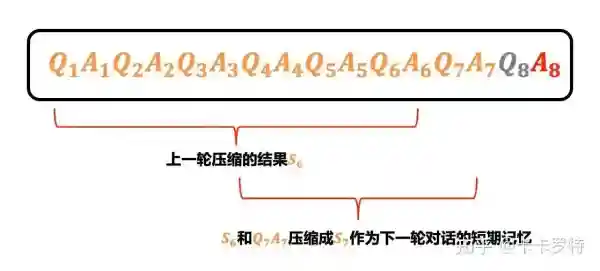
例如你可以开启另外一个和 ChatGPT 的会话,这个会话的目的是对你目前正在使用的会话进行文本摘要提取。
甚至我们在用大型语言模型给对话历史做摘要的时候,还可以设定要求,要求它把生成的 token 数量控制在一定范围内,这样我们就能和 ChatGPT 永远对话下去。但需要注意的是,随着对话轮数的增多,必然有一部分信息会被过滤掉。
方案三:
将方案一和方案二结合起来,只对最近 k 轮对话进行文本摘要的提取。这进一步的压缩了短期记忆的 token 数。
方案四:
设计一些更复杂的短期记忆压缩方案。例如通过实体抽取将对话中的重要实体和内容抽取出来,利用知识图谱将对话中的关系对组织出来等等。
方案四涉及到更复杂的提示工程,也涉及到自然语言处理的一些基本知识,对这部分感兴趣读者可以参考 LangChain 中 ConversationEntityMemory 和 ConversationKGMemory 的实现 [②]。
2.4 长期记忆
2.4.1 什么是长期记忆
长期记忆是短期记忆的相对概念。短期记忆的生命周期只存在于一次会话中,当会话完全结束后,短期记忆就不存在了。而长期记忆可以一直存储和访问。就像人类大脑会对一些重要信息进行长期记忆一样。
实现长期记忆最好的方法是将整个大型语言模型进行 finetune,将您想要它记住和理解的内容调整到模型的权重中。
然而,finetune 会带来两个挑战。一方面,finetune 对数据量有一定的要求,数据量过小难以获得好的效果。另一方面,finetune 对算力的要求非常高。目前,OpenAI 尚未开放 ChatGPT 针对自定义数据集的 finetune。但我相信 OpenAI 迟早会开放这个功能。
那么,除了 finetune,还有其他的方法来存储长期记忆吗?答案是有的。最简单的方法是将长期记忆存储在外部数据库中,当与 ChatGPT 开始对话时,从数据库中提取长期记忆,并将其作为提示(prompt)输入到 ChatGPT 中。
这种方法理论上可以解决长期记忆的问题,本质上是通过上下文学习完全代替 finetune。但是这种方法存在一个严重的缺陷,因为 ChatGPT 的神经网络结构决定它只能处理最多 4096 个 token。而长期记忆通常涉及到非常多的 token,例如用户编写的工程代码、用户想要 ChatGPT 记住的文档,甚至是书籍等等。
2.4.2 如何间接存储长期记忆
实际上,我们有更巧妙的方法来解决前面小节提到的问题。解决方法的思路非常类似于推荐系统中的召回策略。
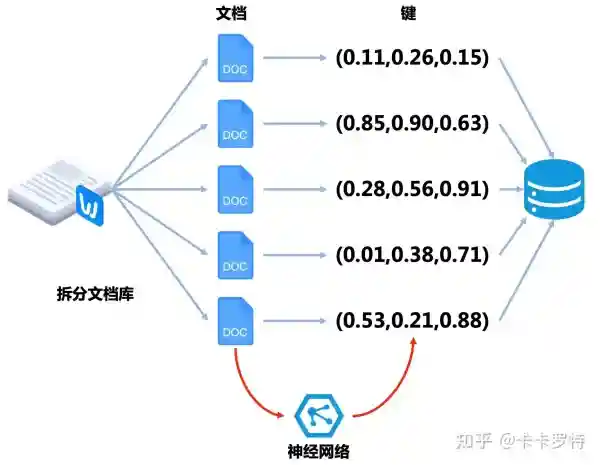
假设我们希望 ChatGPT 记住的长期记忆是一个文档,首先我们将文档进行分片,将文档拆分成一份份的,每一份的 token 数不会太大,以保证每一份都能完全塞入 ChatGPT 中。
![图片[3]-ChatGPT 实用指南(二)-SPHAI人工智能聊天 | GPT-3.5](https://ai.sph.net/wp-content/uploads/2023/04/4cb88b0babffe67.webp)
紧接着我们利用神经网络 [③] 将每一份文档进行编码。这个神经网络输入的是文档,输出的是一个向量编码。这个向量编码可以理解为神经网络对文档内容进行了高度的压缩。然后我们将编码的结果存储在 向量数据库 中。
向量数据库是一种特殊的数据库,它的键是向量而不是一个数。在我们的场景下,这个向量数据库的键是文档的向量,对应的值是对应的文档。
到目前为止准备工作已经准备就绪。接下来我们将演示如何通过这套系统完成 间接的长期记忆。
当用户向 ChatGPT 提出一个问题时,我们先将他的提问文本塞入到之前的神经网络中,该神经网络将用户的提问编码成向量。然后将编码的向量去向量数据库中查询,查询的结果是和提问编码向量最接近的向量(这里的接近一般是指向量的余弦相似度或欧氏距离)。然后我们将查询到的向量对应的文档作为提示(prompt)给到 ChatGPT,至此我们完成了长期记忆的查询。
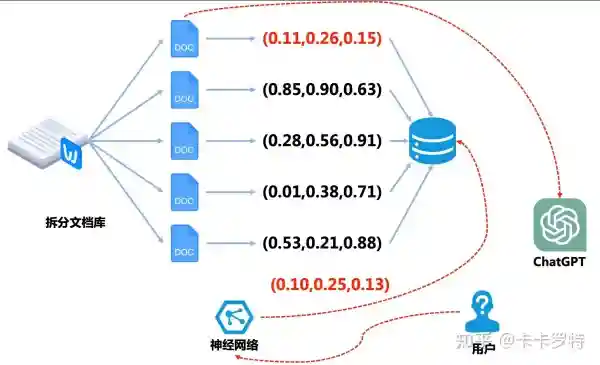
例如在上图中,用户的提问被编成成 (0.10,0.25,0.13)(0.10,0.25,0.13) ,在向量数据库中,查询到最接近的向量是 (0.11,0.26,0.15)(0.11,0.26,0.15) ,对应的文档是第一个子文档。
不难看到,这种思路是根据用户的提问召回相关的文档。然后将文档加工成对应的提示给到 ChatGPT,然后让 ChatGPT 完成后续的任务。
2.5 外部工具
2.5.1 为什么需要外部工具
一方面使用工具是具有智能的表现之一,另一方面虽然人类拥有智能,但并不擅长所有的任务,例如,准确计算大量数字或快速查询大量文档都是相对较为困难的任务。对于 ChatGPT 这样的大型语言模型也是如此,它虽然具备强大的语言处理能力,但并不擅长进行符号计算、实时信息获取或代码的执行。
正是由于 ChatGPT 在某些任务上表现不佳,因此我们需要让它学会使用外部工具,以使其变得更加强大。
除此之外,我们需要认识到 ChatGPT 的真正优势所在。它的强大之处并不在于总能够给出准确无误的答案,相反,ChatGPT 有时会说一些无关紧要的话。ChatGPT 真正的优势在于其能够清晰地理解以自然语言给出的指令。因此,基于这一特性,我们可以让 ChatGPT 充当中央控制器,自动查找适合的工具,并在适当的时候使用它们。例如,当 ChatGPT 需要进行数字计算时,我们可以让它自动调用计算器程序进行辅助计算。同样地,当 ChatGPT 无法实时获取最新消息和信息时,我们可以让它使用搜索引擎搜索实时新闻和信息。另外,如果 ChatGPT 无法模拟运行非常复杂的代码,我们可以让它调用相应的解释器、编译器或虚拟机。
熟悉强化学习的读者可以看出,当 ChatGPT 使用外部工具时,我们可以将其视为强化学习中的智能体 agent,通过与 环境 交互以实现任务。
2.5.2 如何使用外部工具
在讲解两种具体方法之前,我们首先说明一下 ChatGPT 使用外部工具的整体思路。
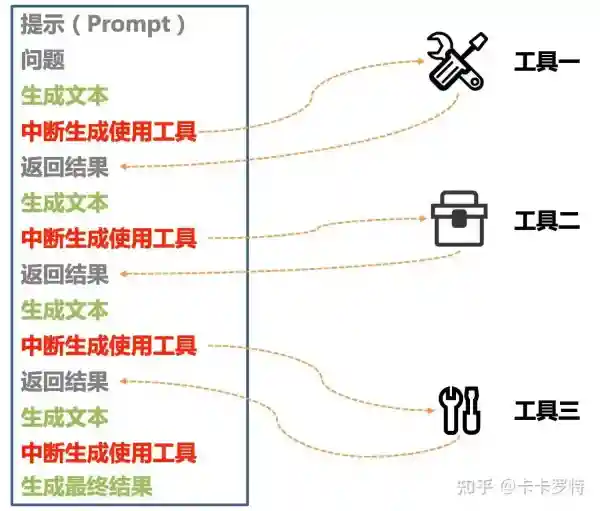
首先,我们需要设计一个提示,这个提示包含了解决问题的步骤和工具的使用。接着我们提出我们要解决的问题,将提示和问题一起给到 ChatGPT。
然后 ChatGPT 会开始生成文本。其中会出现使用某个工具的 token。例如 搜索(三体的作者是谁) 。当出现了使用工具的 token 后,ChatGPT 停止文本生成。根据事先写好的接口开始使用工具。例如调用搜索引擎的接口搜索 三体的作者是谁。
接着工具的结果返回给 ChatGPT ,并和前文的内容组成新的提示(Prompt)发送给 ChatGPT。
最后 ChatGPT 根据新的提示(Prompt)再次生成文本,开始重复前面的步骤。不断重复直到 ChatGPT 停止使用工具得到最终的答案。
下面我们讲解两个经典的使用外部工具的例子,分别是 ReAct 框架和 self-ask 框架,它们都属于使用工具的提示工程。
由于这两个框架的提示都是用的英文,为了方便复现,我们以英文的对话为例(这里主要参考 LangChain 库)。
ReAct 框架:
ReAct 是 Resoning 和 Acting 的缩写。这个框架的基本思想是给一个 Prompt,这个 Prompt 将 Question 拆成几个步骤。分别是:
- Tought: 面对这个 Question 我下一步应该做什么。
- Action:执行某个动作。在 ReAct 里有三种动作,第一个是 Search[entity] 如果存在对应实体的维基页面,则返回前5句话,否则使用维基百科搜索引擎搜索前5个类似的实体;第二个是 Look[sring] 它将返回包含该字符串的页面中的下一句话,模拟浏览器上的 Ctrl+F 功能。第三个是 Finish[answer] 它将使用答案完成当前任务。
- Observation:观察到的外部工具给到的结果,将作为新的提示输入给 ChatGPT。
在 LangChain 中 ReAct 框架的提示如下:
Question: What is the elevation range for the area that the eastern sector of the
Colorado orogeny extends into?
Thought 1: I need to search Colorado orogeny, find the area that the eastern sector
of the Colorado orogeny extends into, then find the elevation range of the
area.
Action 1: Search[Colorado orogeny]
Observation 1: The Colorado orogeny was an episode of mountain building (an orogeny) in
Colorado and surrounding areas.
Thought 2: It does not mention the eastern sector. So I need to look up eastern
sector.
Action 2: Lookup[eastern sector]
Observation 2: (Result 1 / 1) The eastern sector extends into the High Plains and is called
the Central Plains orogeny.
Thought 3: The eastern sector of Colorado orogeny extends into the High Plains. So I
need to search High Plains and find its elevation range.
Action 3: Search[High Plains]
Observation 3: High Plains refers to one of two distinct land regions
Thought 4: I need to instead search High Plains (United States).
Action 4: Search[High Plains (United States)]
Observation 4: The High Plains are a subregion of the Great Plains. From east to west, the
High Plains rise in elevation from around 1,800 to 7,000 ft (550 to 2,130
m).[3]
Thought 5: High Plains rise in elevation from around 1,800 to 7,000 ft, so the answer
is 1,800 to 7,000 ft.
Action 5: Finish[1,800 to 7,000 ft]
Question: Musician and satirist Allie Goertz wrote a song about the "The Simpsons"
character Milhouse, who Matt Groening named after who?
Thought 1: The question simplifies to "The Simpsons" character Milhouse is named after
who. I only need to search Milhouse and find who it is named after.
Action 1: Search[Milhouse]
Observation 1: Milhouse Mussolini Van Houten is a recurring character in the Fox animated
television series The Simpsons voiced by Pamela Hayden and created by Matt
Groening.
Thought 2: The paragraph does not tell who Milhouse is named after, maybe I can look up
"named after".
Action 2: Lookup[named after]
Observation 2: (Result 1 / 1) Milhouse was named after U.S. president Richard Nixon, whose
middle name was Milhous.
Thought 3: Milhouse was named after U.S. president Richard Nixon, so the answer is
Richard Nixon.
Action 3: Finish[Richard Nixon]
Question: Which documentary is about Finnish rock groups, Adam Clayton Powell or The
Saimaa Gesture?
Thought 1: I need to search Adam Clayton Powell and The Saimaa Gesture, and find which
documentary is about Finnish rock groups.
Action 1: Search[Adam Clayton Powell]
Observation 1 Could not find [Adam Clayton Powell]. Similar: [’Adam Clayton Powell
III’, ’Seventh Avenue (Manhattan)’, ’Adam Clayton Powell Jr. State Office
Building’, ’Isabel Washington Powell’, ’Adam Powell’, ’Adam Clayton Powell
(film)’, ’Giancarlo Esposito’].
Thought 2: To find the documentary, I can search Adam Clayton Powell (film).
Action 2: Search[Adam Clayton Powell (film)]
Observation 2: Adam Clayton Powell is a 1989 American documentary film directed by
Richard Kilberg. The film is about the rise and fall of influential
African-American politician Adam Clayton Powell Jr.[3][4] It was later aired
as part of the PBS series The American Experience.
Thought 3: Adam Clayton Powell (film) is a documentary about an African-American
politician, not Finnish rock groups. So the documentary about Finnish rock
groups must instead be The Saimaa Gesture.
Action 3: Finish[The Saimaa Gesture]
Question: What profession does Nicholas Ray and Elia Kazan have in common?
Thought 1: I need to search Nicholas Ray and Elia Kazan, find their professions, then
find the profession they have in common.
Action 1: Search[Nicholas Ray]
Observation 1: Nicholas Ray (born Raymond Nicholas Kienzle Jr., August 7, 1911 - June 16,
1979) was an American film director, screenwriter, and actor best known for
the 1955 film Rebel Without a Cause.
Thought 2: Professions of Nicholas Ray are director, screenwriter, and actor. I need
to search Elia Kazan next and find his professions.
Action 2: Search[Elia Kazan]
Observation 2: Elia Kazan was an American film and theatre director, producer, screenwriter
and actor.
Thought 3: Professions of Elia Kazan are director, producer, screenwriter, and actor.
So profession Nicholas Ray and Elia Kazan have in common is director,
screenwriter, and actor.
Action 3: Finish[director, screenwriter, actor]
Question: Which magazine was started first Arthur’s Magazine or First for Women?
Thought 1: I need to search Arthur’s Magazine and First for Women, and find which was
started first.
Action 1: Search[Arthur’s Magazine]
Observation 1: Arthur’s Magazine (1844-1846) was an American literary periodical published
in Philadelphia in the 19th century.
Thought 2: Arthur’s Magazine was started in 1844. I need to search First for Women
next.
Action 2: Search[First for Women]
Observation 2: First for Women is a woman’s magazine published by Bauer Media Group in the
USA.[1] The magazine was started in 1989.
Thought 3: First for Women was started in 1989. 1844 (Arthur’s Magazine) < 1989 (First
for Women), so Arthur’s Magazine was started first.
Action 3: Finish[Arthur’s Magazine]
Question: Were Pavel Urysohn and Leonid Levin known for the same type of work?
Thought 1: I need to search Pavel Urysohn and Leonid Levin, find their types of work,
then find if they are the same.
Action 1: Search[Pavel Urysohn]
Observation 1: Pavel Samuilovich Urysohn (February 3, 1898 - August 17, 1924) was a Soviet
mathematician who is best known for his contributions in dimension theory.
Thought 2: Pavel Urysohn is a mathematician. I need to search Leonid Levin next and
find its type of work.
Action 2: Search[Leonid Levin]
Observation 2: Leonid Anatolievich Levin is a Soviet-American mathematician and computer
scientist.
Thought 3: Leonid Levin is a mathematician and computer scientist. So Pavel Urysohn
and Leonid Levin have the same type of work.
Action 3: Finish[yes]
Question: Author David Chanoff has collaborated with a U.S. Navy admiral who served as the ambassador to the United Kingdom under which President?其中,前面部分属于少样本学习中的示例,目的是教会 ChatGPT 如何使用工具。最后一行的 Question 就是我们要问 ChatGPT 的问题。对于这个问题,ChatGPT 将使用外部工具解答。具体的结果如下:
Thought 1: I need to search David Chanoff and the U.S. Navy admiral, find the ambassador to the United Kingdom, then find the President they served under.
Action 1: Search[David Chanoff]
Observation 1: David Chanoff is an American author and journalist. He is the co-author of
several books, including Inside the Mirage: America's Fragile Partnership
with Saudi Arabia (2004) and The Game Player: Confessions of the CIA's
Original Political Operative (1989).
Thought 2: I need to search the U.S. Navy admiral David Chanoff collaborated with.
Action 2: Search[U.S. Navy admiral]
Observation 2: Admiral Charles R. Larson was a United States Navy four-star admiral who
served as the United States Ambassador to the United Kingdom from 1998 to
2001.
Thought 3: Admiral Charles R. Larson served as the United States Ambassador to the
United Kingdom from 1998 to 2001. So the President they served under is
Bill Clinton.
Action 3: Finish[Bill Clinton]self-ask 框架:
self-ask 是指提出子问题的过程。其基本思想是让 ChatGPT 判断是否需要提出子问题。如果需要,ChatGPT 将自行提出子问题,先解决子问题,再解决主问题。这个思路在工作记忆一节中已经为大家演示过。但是,在这里,我们将引入一个外部工具——搜索引擎。
ChatGPT 自己提出的子问题将直接送到搜索引擎中,然后将搜索结果返回给 ChatGPT。
下面,我们将以 self-ask 原始论文中的例子来演示这个过程。
首先是给到提示(prompt):
Question: Who lived longer, Theodor Haecker or Harry Vaughan Watkins?
Are follow up questions needed here: Yes.
Follow up: How old was Theodor Haecker when he died? Intermediate answer: Theodor Haecker was 65 years old when he died.
Follow up: How old was Harry Vaughan Watkins when he died? Intermediate answer: Harry Vaughan Watkins was 69 years old when he died.
So the final answer is: Harry Vaughan Watkins.提示中有四个要素:
- Quesion: 要解决的问题。
- Are follow up questions needed here: 是否要提出子问题。
- Follow up: 如果要提出子问题,提出的子问题。
- Intermediate answer: 来自搜索引擎的结果。注意这里只是提示。
- So the final answer is: 如果能得出最终结论,则返回最终结论。
然后我们提出我们想解决的问题:
Question: In what year was the current tallest wooden lattice tower completed?
Are follow up questions needed here:接着 ChatGPT 开始生成文本:
Yes.
Follow up: What is the current tallest wooden lattice tower?停止文本生成,将子问题结果给到外部工具搜索引擎,得到结果,将结果返回到 Intermediate answer: 中。
此时的提示更新为这样:
Question: Who lived longer, Theodor Haecker or Harry Vaughan Watkins?
Are follow up questions needed here: Yes.
Follow up: How old was Theodor Haecker when he died? Intermediate answer: Theodor Haecker was 65 years old when he died.
Follow up: How old was Harry Vaughan Watkins when he died? Intermediate answer: Harry Vaughan Watkins was 69 years old when he died.
So the final answer is: Harry Vaughan Watkins.
Question: In what year was the current tallest wooden lattice tower completed?
Are follow up questions needed here: Yes.
Follow up: What is the current tallest wooden lattice tower?
Intermediate answer: Radio Tower Gliwice.接着继续将提示给到 ChatGPT,得到生成文本:
Follow up: When was Gliwice Radio Tower completed?停止文本生成,将子问题结果给到外部工具搜索引擎,得到结果,将结果返回到 Intermediate answer: 中。
此时的提示更新为这样:
Question: Who lived longer, Theodor Haecker or Harry Vaughan Watkins?
Are follow up questions needed here: Yes.
Follow up: How old was Theodor Haecker when he died? Intermediate answer: Theodor Haecker was 65 years old when he died.
Follow up: How old was Harry Vaughan Watkins when he died? Intermediate answer: Harry Vaughan Watkins was 69 years old when he died.
So the final answer is: Harry Vaughan Watkins.
Question: In what year was the current tallest wooden lattice tower completed?
Are follow up questions needed here: Yes.
Follow up: What is the current tallest wooden lattice tower?
Intermediate answer: Radio Tower Gliwice.
Follow up: When was Gliwice Radio Tower completed?
Intermediate answer: 1935.然后将提示给到 ChatGPT,得到以下输出:
So the final answer is: 1935.对话完成,得到了最终的答案。
2.6 OpenAI 接口的参数详解
使用 ChatGPT 有两种方式。第一种是通过官方的 Web 界面直接访问,二是通过程序接口访问 ChatGPT。使用第二种方式更好,原因有二:
- 基于程序接口可以做二次开发和个人定制,制作更适合个人和企业的入口。
- 基于程序接口可以调整更多的参数,让 ChatGPT 的回答更加的符合你的要求。
下面我们对 OpenAI 官方的接口参数进行详细的解读。
model 参数:
通过输入不同的 model ID 选择使用不同的大型语言模型,该参数是必选参数。例如 text-davinci-003 。
prompt 参数:
输入给模型的提示,这是可选参数,可以不设置。如果不设置默认是 <|endoftext|>。<|endoftext|> 是 OpenAI 定义的文本生成终止符号,当模型预测输出这个 token 时,文本生成将终止。
suffix 参数:
完成生成文本后的后缀字符串,默认为空。表示在由 ChatGPT 生成的文本后面会加上 suffix 设置的字符串。
max_tokens 参数:
ChatGPT 生成 token 的最大数量,默认为 16。需要注意的是,这里 token 和我们人类理解的字符并不一样,关于这部分的内容可以参考前面的 1.2.3 。
temperature 参数:
采样的温度(temperature)参数,默认值为 1 ,可选择范围是 [0,2] 之间,较高的值(如1.5)将使输出更加随机,而较低的值(例如0.2)将使其更加集中和确定。关于温度参数的原理可以参考 1.2.4 小节。
top_p 参数:
核采样参数,默认值为 1, 可选择范围是 (0,1] 之间。关于核采样的原理可参考 1.2.4 小节。
需要注意的是,不建议 top_p 参数和 temperature 参数同时修改,一般只修改其中的一个。
n 参数:
表示要生成多少次文本。默认值是 1 。例如当 $n=3$ 时,ChatGPT 会根据你的输入生成 3 次。这 3 次一般是不相同的,因为采样是随机的。$n>1$ 比较适合于同一个问题生成多个候选答案的场景。
stream 参数:
默认值是 false。当设置为 false 时,ChatGPT 一次性返回所有文本生成结果。当设置为 true 时间,ChatGPT 一个个返回文本的生成结果。需要注意的是,ChatGPT 一个个返回文本的生成结果也是在服务器端全生成完后,才一个个返回给客户端。
stop 参数:
stop参数用于指定在生成文本时停止生成的条件,当生成文本中包含指定的字符串或达到指定的最大生成长度时,生成过程会自动停止。最多包含 4 个停止符号。需要注意的是返回的文本将不包含停止序列。默认参数是 null(表示没有,此时仅使用 ChatGPT 自己的停止符号)。当我们要设计自己的外部工具时,可以使用该参数。关于外部工具的使用原理可以参考 2.5.2 小节。
logit_bias 参数:
接受一个 json 对象,大概长这个样子:
{30243:-100,40684:-100}其中 json 的键 30243,40684 表示 GPT 的 token 表编号。通过该工具可以查询。例如上面的例子中,这两个 token 分别表示 machine 和 learning 两个字符。
json 的值 -100,-100 表示对应的 token 在后续文本生成中被采样到的几率。它的范围在 [-100,100] 之间。其中 -100 表示对应的 token 不会在后面的文本生成中出现,100 表示对应的 token 一定会在后面的文本中出现。
presence_penalty 和 frequency_penalty 参数:
这两个参数的范围都在 [-2,2] 之间。值大于 0 表示文本生成将尽量减少出现重复的 token。
- presence_penalty 是通过前文 token 是否出现了来控制重复 token 的出现。
- frequency_penalty 是通过前文 token 出现的频率来控制重复 token 的出现。
它们使用如下公式来控制:
mu[j] -> mu[j] - c[j] * frequency_penalty - float(c[j] > 0) * presence_penalty其中 mu[j] 表示现在生成的 token 选择 j 编号 token 的概率值。
c[j] 表示 j 编号 token 在当前位置之前出现(被采样)的频率。
float(c[j] > 0) 表示 j 编号 token 是否在当前位置之前出现过。
很明显,当 frequency_penalty 和 presence_penalty 均为 0 时,文本生成的过程与前面讲述的相同。当它们均大于 0 时,模型倾向于尽量减少重复的 token,反之,则倾向于尽量增加重复的 token。
① 在最开始,提示是一种文本数据处理的方法,它将自然语言的子任务通过提示统一成文本生成任务。例如对如下的文本分类问题(情感识别):
文本数据:《三体》这本书很棒! 情感标签:正向
通过提示将上述数据变成如下形式:
《三体》这本书很棒,这句话的情感评论是 正向。
这句话的情感评论是 是提示,它将文本分类问题改装成了文本生成问题。除了这种提示以外,提示还有这更丰富的内涵。
② LangChain 是一个用于构建基于大型语言模型(LLM)的应用程序的开源库。它可以帮助开发者将LLM 与其他计算或知识源结合起来,创建更强大的应用程序。
③ 这里的神经网络可以是 OpenAI 提供的文本 embedding 服务,也可以是 huggingface 上的各类文本 embedding 模型,甚至是预训练的 bert 模型也是可以的。
知乎卡卡罗特:https://zhuanlan.zhihu.com/p/620445986

请登录后查看评论内容